Swear
Words
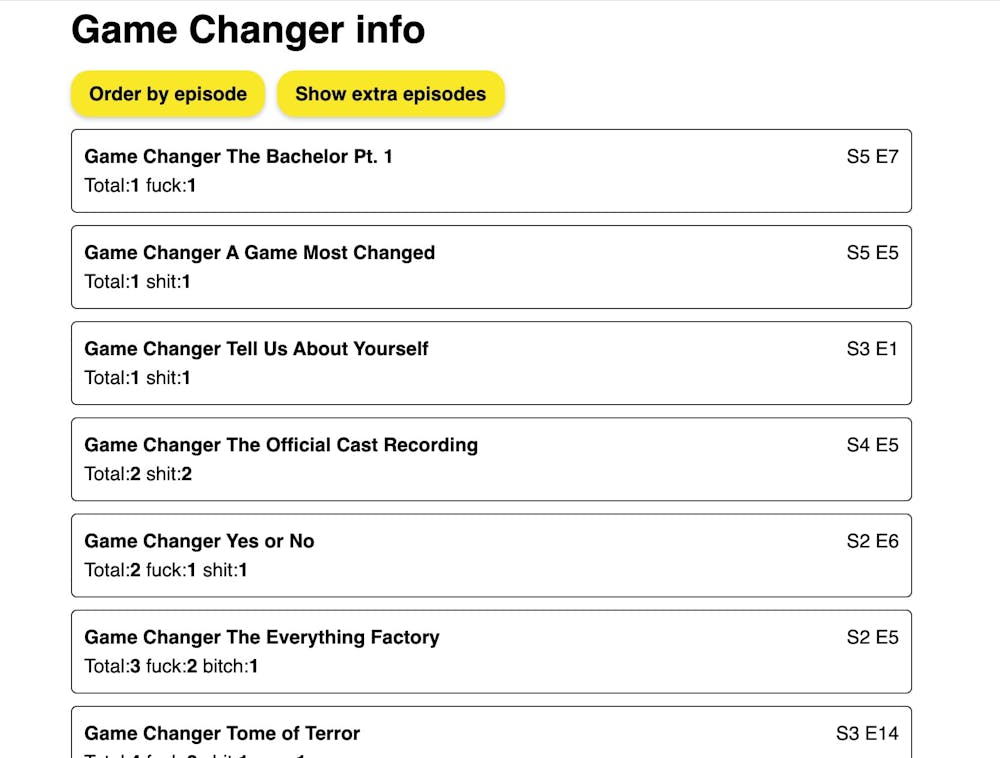
My wife and I have been loving the Dropout.tv show Game Changer. But we've found it a bit difficult for us to share episodes with my in-laws. Browsing the Dropout subreddit I found other users having the same issue.
The solution, a site that has the number of swear words per episode.
Data
The first step, get all the video URLs. The sitemap.xml provides a great overview of all the episodes, and regexing I got all the urls that contain game changer.
With URLs in hand, we now need to get the transcripts of each video. When enabling subtitles the browser receives a single file with the full transcript of the video.
It seems like the easiest way to get the transcripts is going to be through the subtitles, but this requires a session (logged in) and is from an iframe, so we're probably going to have to use a browser based scraping tool.
Violentmonkey is a chrome plugin for automating scripts on websites, someone had already made a script to interact with the video iframe to enable the subtitles. This is perfect but we're not going to use Violentmonkey, we're going to use puppeteer a javascript tool that uses chrominum to run a browser session.
Next step, write a script that will
- Log into dropout.tv
- Go to a video, and enable subtitles
- Collect some meta data from the page (episode, season...)
- Wait for the transcript to be sent
- Go to the next video, and loop until it's done
I'll share the most interesting scripts:
Selecting the subtitles, this is run by puppeteer in browser.
await page.evaluate(() => {
const iframe = document.getElementById("watch-embed");
// if we found the iframe
if (iframe) {
// add the api=1 to the src
iframe.src += "&api=1";
// create a new player
const player = new VHX.Player("watch-embed");
// when the video is loaded
player.on("loadeddata", (event) => {
// get the subtitles
const languages = player.getSubtitles();
// if there are subtitles
if (languages.length > 0) {
// set the first subtitle
player.setSubtitle(languages[0].language);
}
});
}
});Waiting for the transcript to be loaded:
await new Promise((resolve) => {
const callback = (response) => {
if (response.url().includes(".vtt")) {
transcripts.push({ url, vtt: response.url(), meta: content });
page.off("response", callback);
fs.writeFileSync(
"transcripts.json",
JSON.stringify(transcripts, null, 2)
);
resolve();
}
};
page.on("response", callback);
});Parsing the data
Now that we have the data, we just go through each transcript with a list of cuss words, and collecting the totals of each.
const getSwearWords = (filename) => {=
const swearWords = [...cuss words...];
const text = fs
.readFileSync(`./downloads/${filename}.vtt`, "utf-8")
.toLowerCase();
const out = {};
swearWords.forEach((word) => {
const newText = text;
out[word.trim()] = newText.split(word).length - 1;
});
return out;
};We then package up all this into a nice json
UI
As always I threw together a simple vue app with vite.