Usecase
of GPT

In my day-to-day at Rangle.io, we're knee-deep in design systems, and as part of our knowledge-sharing culture, we produce tons of insightful blog posts. However, keeping up with all of the content can feel daunting. I was thinking this could be a good use case for Chat GPT's API - it seemed like the perfect tool to create concise summaries of our blog posts to help me (and others) keep up to date with blog posts.
I already had access to Chat GPT's API from a side project I was dabbling in. It was a Python project with the necessary setup, making it the perfect launchpad for this new experiment.
The first step was to gather all the blog post URLs. Rangle.io employs a robust CMS named Sanity. Looking at the API for Sanity and Rangle's site I found the list of all the blog posts in one of the API requests.
import requests
import json
res = requests.get('https://d367if72.api.sanity.io/v2021-10-21/data/query/production?query=*%5B_type%20%3D%3D%20%22blogPost%22%0A%20%26%26%20!(_id%20in%20path(%27drafts.**%27))%20%26%26%20%22ds%22%20in%20topicTags%5B%5D-%3E.id%5D%20%7C%20order(publishDate%20desc)%5B0...99%5D%0A%7B%0A%20%20%22id%22%3A%20_id%2C%0A%20%20blogTitle%2C%0A%20%20publishDate%2C%0A%20%20summary%2C%0A%20%20slug%2C%0A%7D%0A%0A')
with open('blogPosts.json', 'w') as file:
json.dump(res.json(), file)This query looks like gibberish but by putting it through a URL decoder you get an easier-to-read query
https://d367if72.api.sanity.io/v2021-10-21/data/query/production?query=*[_type == "blogPost"
&& !(_id in path('drafts.**')) && "ds" in topicTags[]->.id] | order(publishDate desc)[0...99]
{
"id": _id,
blogTitle,
publishDate,
summary,
slug,
}Having compiled the list of all blog post pages, we now scrape the HTML pages rather than navigating through Sanity's API.
With Beautiful Soup, I parsed the text from the HTML, effectively preparing the data for Chat GPT.
import requests
import json
from bs4 import BeautifulSoup
with open('blogPosts.json') as json_file:
blogPosts = json.load(json_file)['result']
for blogPost in blogPosts:
print('scraping blog post %s'%blogPost['slug'])
res = requests.get('https://rangle.io/blog/%s'%blogPost['slug'])
soup = BeautifulSoup(res.text, 'html.parser')
with open('blogPosts/%s.txt'%blogPost['slug'], 'w') as outfile:
for p in soup.find('article').find_all('p'):
outfile.write(p.text + '\n')Then fed each article into Chat GPT, storing the returned responses. I initially considered having GPT output the data in JSON format (which can be unreliable), so in the interest of a more reliable structure, I opted for lists.
import requests
import json
import os
context = '''
convert the content into point form
each point should have enough context to be understood and useful
each point should provide a piece of wisdom or insight
be very informative and to the point
do not use any filler words
'''
texts = []
for filename in os.listdir('blogPosts'):
with open('blogPosts/%s'%filename) as file:
name = filename.split('.')[0]
texts.append({'title':name,'text':file.read()})
summaries = []
for text in texts:
try:
data = {
'model':'gpt-3.5-turbo',
'messages':[
{
'role':"system",
'content': context
},
{
'role':"user",
'content': text['text'] # the content of the blog post
}
]
}
config = {
'headers': {
'Authorization': f'Bearer {apiKey}',
},
}
response = requests.post('https://api.openai.com/v1/chat/completions', json=data, headers=config['headers'])
summary = response.json()['choices'][0]['message']['content']
summaries.append(summary)
# add to a file text
with open('summaries.txt', 'a') as file:
file.write(summary)
except:
print('error')Looking at the responses, some of the summaries were more like advice than summaries. This sparked the idea of a "Guru" bot - a kind of AI that provides random advice on Design System related topics.
Next was to format the data to be useable for the site, basically transforming the text into a JSON object with arrays of summaries via find and replace operations.
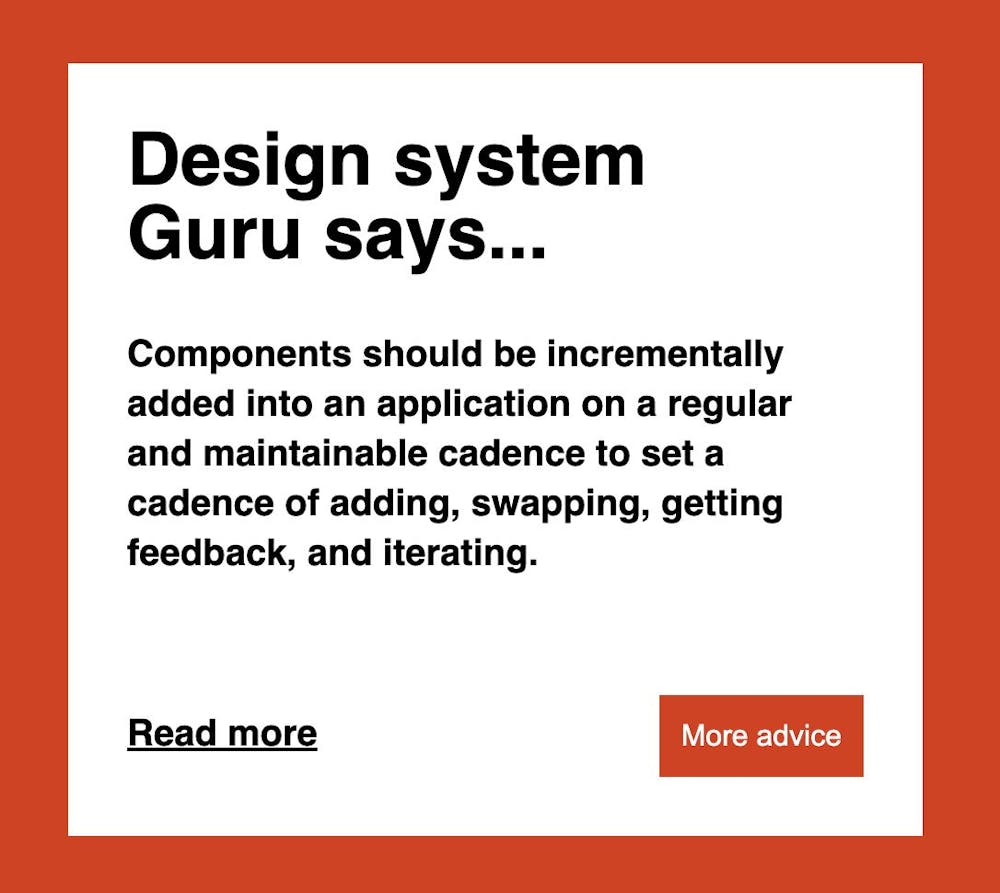
With the data all set, I initialized a Vite TypeScript project, implementing a feature that randomizes the piece of content to display. This way, each visit offers a fresh piece of summarized knowledge with a link out to the related blog post.